|
GPU并行計算介紹當前GPU并行計算十分火熱,在人工智能、大數(shù)據(jù)的應用非常廣泛,在目前我們的工作中雖然很少接觸到并行計算,但了解GPU并行計算的一些簡單原理有利于日后接觸的時候更快上手。 1GPU架構(gòu) 如今僅通過提高主頻的方式增強計算能力的方式已經(jīng)很難滿足海量數(shù)據(jù)的計算量需求,以GPU(圖形處理器)為代表的眾核計算不斷興起。在以前GPU僅僅只應用于圖像顯示,而如今隨著GPU 中核心數(shù)和計算能力的不斷提升,計算架構(gòu)不斷完善,因此提出了利用圖形處理器來計算原本由中央處理器處理的計算任務(wù)。
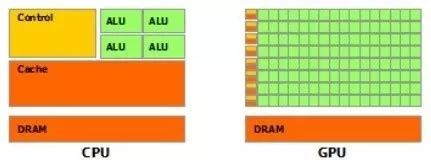
GPU和CPU簡單結(jié)構(gòu)示意圖 簡單的講,如上圖中CPU結(jié)構(gòu)上比GPU復雜得多,但GPU最直觀的感受是計算單元非常多,這眾多的計算單元直接決定了GPU非常適用于計算而非邏輯判斷。例如在一些矩陣的運算(在機器學習中大量應用)是非常適用于GPU計算的。 2SIMT體系
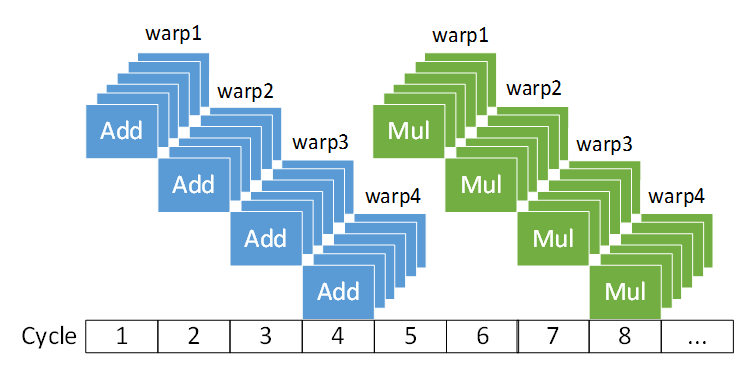
SIMT執(zhí)行示意圖 GPU 的SIMT 的執(zhí)行模型,即單指令多線程的并行執(zhí)行模型。上圖即為GPU的SIMT的一個簡單示例,其中warp是線程簇,下方為時間周期。上圖中每個周期運行對多個線程運行相同的指令。同時結(jié)合類似流水線的特性,當前指令執(zhí)行完畢時,即圖中前四個周期結(jié)束時,下一個乘法指令已經(jīng)準備就緒可以立即執(zhí)行了。 3線程分歧
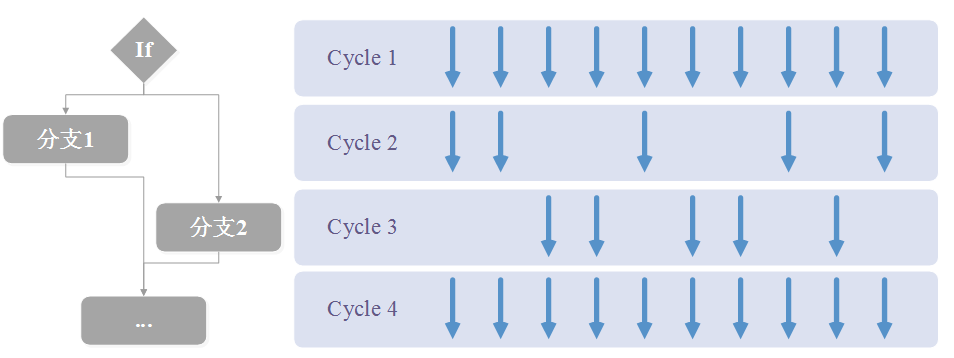
線程分歧示意圖 由于GPU 并行計算中采用SIMT 的計算體系,相同線程簇中的線程在同一時間周期執(zhí)行相同的指令,因此當設(shè)計的程序出現(xiàn)比較多的分支時,會出現(xiàn)明顯的線程分歧,造成性能的下降。如上圖中當程序出現(xiàn)分支時,有一部分線程執(zhí)行當前分支,其他線程需要等待。在下一個時序中,程序執(zhí)行另一個分支,部分線程執(zhí)行該分支,而其他不屬于該分支的線程需要等待。當最后結(jié)束分支時,所有線程才能繼續(xù)同時執(zhí)行其他代碼。我們可以得出在當出現(xiàn)分支時,是需要部分線程進行等待的,不能最大化利用GPU 的計算資源,會造成效率的下降。 |